
PDF Extractor SDK "Windows" programinės įrangos kūrėjams: PDF į tekstą, PDF į XML, PDF atvaizdus, PDF formato perskaitymą, "PDF" formatu "CSV" Excel.
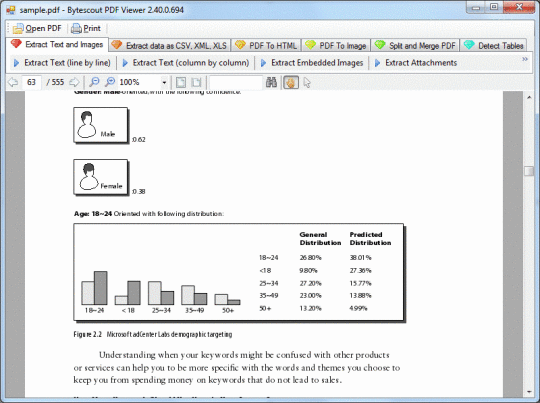
Bytescout PDF Extractor SDK leidžia konvertuoti PDF į tekstą, PDF į XML, PDF į CSV, išgauti atvaizdus iš PDF, išgauti informaciją apie PDF failus. NET ir ActiveX sąsajose be jokios papildomos programinės įrangos.
Privalumai:
konvertuoja PDF į paprastą tekstą (ir gali sekti stulpelius, jei konvertuosite laikraštį PDF formatu), įskaitant nematomą teksto ištraukimą;
konvertuoja lenteles į PDF į Excel (CSV), skaitant langelius iš pateikto stačiakampio;
konvertuoja lenteles į PDF į XML failus;
ištraukia PDF failo metaduomenis (pavadinimą, autorių, aprašymą) ir kitą informaciją apie failą (puslapių skaičius, užšifruotas arba ne);
ištraukia įterptus vaizdus iš PDF dokumento (ASP.NET, VB.NET, C #, VB6 ir VBScript);
DocumentMerger ir DocumentSplitter sąsajos ir klases sujungti ir padalinti PDF dokumentus;
nereikia įdiegti "Adobe Reader" ar bet kurios kitos PDF skaitytuvo programinės įrangos;
teikia .NET ir ActiveX sąsajas;
sudarytas iš 100% valdomo C # kodo.
Kas naujo šiame leidime:
9.0.0.3079 versija: pridėta ištraukto turinio filtravimas pagal šrifto pavadinimą, šrifto dydį ir spalvą.
Atnaujintas OCR variklis pagal naujausią versiją. Atnaujinkite kalbos failus iš "tessdata" aplanko.
Patobulinta teksto ištraukimas, eilučių grupavimas į lentelės duomenis, našumas, XFA formų ištraukimas, TableDetector, fiksuotos PDF analizės problemos.
Kas naujo versijoje 8.7.0.2980:
Pridėta išgauto turinio filtravimas pagal šrifto pavadinimą, šrifto dydį ir spalvą.
Atnaujintas OCR variklis pagal naujausią versiją. Atnaujinkite kalbos failus iš "tessdata" aplanko.
Pagerinta teksto ištraukimas, eilučių grupavimas į lentelės duomenis, našumas, XFA formų ištraukimas, TableDetector, fiksuotos PDF analizės problemos.
Kas naujo versijoje 8.6.0.2911:
Pridėta išgauto turinio filtravimas pagal šrifto pavadinimą, šrifto dydį ir spalvą.
Atnaujintas OCR variklis pagal naujausią versiją. Atnaujinkite kalbos failus iš "tessdata" aplanko.
Patobulinta teksto ištraukimas, eilučių grupavimas į lentelės duomenis, našumas, XFA formų ištraukimas, TableDetector, fiksuotos PDF analizės problemos.
Kas naujo versijoje 8.2.0.2699:
Versija 8.2.0.2699 gali apimti nenustatytus naujinius, patobulinimus ar klaidų taisymus.
Kas naujo versijoje 8.0.0.2528:
Kas naujo versijoje 7.0.0.2474:
Versija 7.0.0.2474:
- pridėjo naują "DocumentPrinter" naudingumo klasę, leidžiančią spausdinti PDF dokumentus tyliai (be jokių vartotojo dialogų)
- pridėta nauja JSONExtractor klasė
- papildytas "DocumentSplitter.Split ()" pakeitimas, leidžiantis nurodyti išvesties aplanką sukurtiems failams
- fiksuoto daugelio sriegimo klaida "DocumentSplitter"
- tableDetector dabar gerbia išskleidimo zoną, nustatytą taikant SetExtractionArea () metodą
- naujos savybės ekstrahavimo klasėse: ExtractionColumns - yra aptiktų stulpelių koordinatės; CustomExtractionColumns - leidžia nepaisyti stulpelių aptikimo
- GetPageRect * metodai neatsižvelgė į puslapio rotaciją.
Ištaisyta klaida diegimo metu, dėl kurios kai kurie ankstesnio diegimo failai trukdė naujinimams - perregistravo registracijos patikrą. Dabar biblioteka nebus išmesti išimties, bet dirbti demo režimu, jei praleidote ar įvesite neteisingą registracijos vardą ir registracijos kodą
- "PDF Multitool": pridėta neseniai dokumentų sąrašo į "Atidaryti PDF dokumentą" mygtuką
- "PDF Multitool": dabar galima pakeisti dydį
- "PDF Multitool": pridėta "Extract JSON" funkcija
- "PDF Multitool": patobulintas lentelės detektoriaus sąsajos
- "PDF Multitool": gerokai patobulinta šriftų perdavimo kokybė
- "PDF Multitool": pridėta derinimo parinktis "Rodyti aptikti ekstrakcijos stulpelius" kontekstiniame meniu, kad būtų rodomi aptariami stulpeliai dabartiniame puslapyje. Pasirodo tik tada, kai paleidžiama bet kokia ištrauka prieš dabartinį rodomą puslapį
- "PDF Multitool": ištaisyta šriftų išdavimo problema 32 bitų "Windows" sistemoje
- kiti smulkūs patobulinimai ir klaidų taisymai
Kas naujo versijoje 6.30.0.2421:
VERSION 6.30.0.2421:
- Pridėta TextComparer naudingumo klasė (prieinama tik ".NET 4.0" asamblėjose), leidžianti palyginti tekstą dviem PDF dokumentais ir generuoti ataskaitą.
- Patobulintas ICC spalvų profilių palaikymas.
- Imporved įterptų šriftų tvarkymas.
- Patobulintas AttachmentExtractor.
- Ištaisytas XMLExtractor.SaveXMLToStream () metodas.
- Ištaisyta teksto kopija, naudojant "OCRCacheMode.WholePage" parinktį.
- Kiti klaidų taisymai ir patobulinimai.
Kas naujo versijoje 6.20.2354:
6.20.2354 versija:
- PDF į tekstą, PDF į CSV, PDF, kad XML funkcijos pagerintos
- Naujas ekstrakto vaizdo įrašas, garso pavyzdžių ištraukimas
- CSV ir XML ekstraktoriai patobulino lentelių tuščius stulpelius
- naujas MultimediaExtractor, norint išgauti vaizdo įrašus ir garso įrašus iš PDF
- naujas turtas PageDataCaching
- naujas pavyzdys "MemoryCareProcessingOfHugeFiles"
- Nustatyta nulinė išimtis bandant išmesti jau išsidėsčiusius puslapius
- XLSExtractor: pagerina šriftų palaikymą
- "SkipInvisibleText" dabar praleidžia apkarpytą tekstą (kuris nematomas)
- pagerintas teksto išvesties apdorojimas
- "XFDF Extractor": pridėta parama žymimuosius laukelius
- Vaizdų išvestis pagerinta, kad būtų galima palaikyti daugiau sub-formatų
- "Unicode" teksto tvarkymas pagerėjo
Kas naujo versijoje 6.11.2149:
6.11.2149 versija:
- Paketinio apdorojimo pavyzdžiai atnaujinami, kad būtų parodytas "Reset ()" metodo naudojimas
- C ++ šaltinio kodo pavyzdys pridėtas puslapių ištraukimui
- DocumentMerger prideda 2 elementų sujungimo metodą Merge2 (inputfile1, inputfile2, outputfile)
- "XLS Extractor" trikčių pataisymai
- "PDF Multitool" dabar leidžia įjungti / išjungti tekstą, vaizdą, vektorių sluoksnius, pridėti papildomų teksto ištraukimo nuostatų.
- XML, CSV, lentelių ištraukimas pagerina palaikymą lenteles su emtpry ląstelėmis stulpelių viduje
- . Patobulintas "ExtractShadowLikeText" turtas: geriau filtruojamas šešėlinis tekstas
Kas naujo versijoje 6.10.2136:
6.10.2136 versija:
- PDF į XML, PDF į CSV, PDF į tekstą funkcijos pagerėjo
- Pridėtas PDF į XLS komandų eilutės pavyzdys (remiantis "VBScript")
- PDF į HTML SDK prideda naują .TextHyperLinks nuosavybę (pagal nutylėjimą TRUE), norint įjungti / išjungti automatinių nuorodų aptikimą tekste
- naujas SearchablePDFMaker (prieinamas PRO licencijoms) konvertuoti PDF į paieškos PDF failus
- naujos savybės ekstraktoriuje: ConsiderFontNames, ConsiderFontSizes, ConsiderFontColors, ConsiderVerticalBorders, CFG bylose
- antraštės stulpelių aptikimas (kai AutoAlighHeaderToColumns = true) patobulintas
- .DetectLinesInsteadOfParagraphs pakeistas nauju. LineGroupingMode, kad valdytumėte, kaip linijos sujungtos į pastraipas
- SVARBU! PDF į XML fiksuoja ilgą laiką problemą su neteisinga Y koordinačių teksto objektams (buvo nukreipta į kairę apačią, o ne į viršutinę kairę).
- .TableXMinIntersectionRequiredInPercents ir .TableYMinIntersectionRequiredInPercents savybės pridėtos
- pridėtas C ++ šaltinio kodo pavyzdys
- XML Extractor pašalina trūkstamus tuščius stulpelius PreserveFormatting = true režimu
- smulkių pataisų spalvos kai kuriuose PDF failuose
- pridėta daugelio OCR kalbų palaikymas
- "PDF Multitool GUI": prideda "Copy to Clipboard" mygtuką į TXT, CSV, XML ir rastrinio vaizdo grotuvo dialogus.
- XLSExtractor: pridedama "PageToWorksheet" nuosavybė, leidžianti įjungti / išjungti atskirų darbo lapų kūrimą viename puslapyje
- naujas nuosavybė .TextEncodingCodePage
- "PDFViewerControl": prideda "ValidateContextMenu", leidžianti vartotojui pridėti pasirinktinius elementus kontekstinio meniu
- "PDF Viewer" valdymas: prideda savybių ShowTextObjects, ShowImageObjects, ShowVectorObjects
- XMLExtractor dabar prideda atpažįstamą tekstą "OCRConfidence"
- PDF / A tikrinimo funkcija (beta versijoje)
- pagerinti kontrolę, teksto tikrinimą ir derinimą pagal originalų išdėstymą. Klausimą sukėlė Y koordinačių perkėlimas valdytuvuose analizuojant: tai buvo neteisinga. Teisingas kelias yra ...
- XML Extractor atnaujinta: dabar žymos langelius ir teksto laukus sukuria CONTROL žyma
- pakeitė dabartinio katalogo naudojimą temp kataloge
- žymės langeliai, "radioboxes", "editbox", "comboboxes" yra geriau palaikomos
- dabar leidžia dalinai patikėti skambintojus
Kas naujo versijoje 5.80.1781:
5.80.1781 versija:
- atnaujinta PDF į XML, PDF į CSV, PDF į teksto funkcionalumą
- OCRMode dabar siūlo 9 režimus
- .DetectLineInsteadOfParagraph dabar veikia daug geriau. Nustatykite klaidingą, kad fiksuotumėte daugialypį tekstą lentelės ląstelėse!
- Patobulintos PDF valdymo priemonės
- FDF ir XFDF duomenų ištraukimas
Kas naujo versijoje 5.10.1747:
5.10.1747 versija:
- Pagerintas PDF į XML, PDF į CSV, PDF į teksto funkcijas
- dabar palaiko teksto ištraukimą iš teksto valdiklių
- XML ištraukėjas dabar prideda šriftų stilių, dydį, pavadinimą, teksto koordinates
- pridėtas OCR pavyzdys ASP.NET
- naujas nuosavybės OCRLanguageDataFolder nurodyti "tessdata" aplanko vietą
- patobulintas PDF failų palaikymas
- pagerina paramą sukamą tekstą
- atnaujinti šaltinio kodo pavyzdžiai
- atnaujinta dokumentacija
- smulkūs patobulinimai ir pataisymai
Kas naujo versijoje 5.00.1626:
5.00.1626 versija:
- Pridėta funkcija OCR (tekstas iš paveikslėlių): dabar galite ištraukti įterptųjų vaizdų tekstą ir pataisyti sugadintą tekstą
- problema, nustatyta naudojant CSV ir XML extractor, trūksta paskutinių stulpelių su kai kuriais parametrais
- patobulintas palaikymas sugadintų PDF failų
- Daugialypis paieškos teksto paieška su žodžių atitikimo režimais dabar palaikomas
- dabar gali ieškoti teksto su brūkšneliais ir skirtingomis eilutėmis: žr. naujo šaltinio kodo pavyzdį. Rasti tekstą su defektais.
- naujas turtas .RTLTextAutoDetectionEnabled (klaidingai pagal numatytuosius nustatymus) RTL kalbų automatiniam aptikimui
- PDF žiūryklės GUI demonstracija pagerėjo
- smulkūs patobulinimai ir pataisymai
Reikalavimai :
. NET Framework 2.0 arba naujesnė
Apribojimai :
"Nag" ekranas, vandens ženklas ant išvesties

Komentarai nerastas